Requires MindStudio login (Google or Apple supported). Trigger a run by providing a URL containing feedback text.
Feedback → Insight → Action
Workflow-based AI system
Problem it solves
Product and stakeholder feedback is abundant, but difficult to act on.
Feedback often arrives:
unstructured and emotionally loaded
mixed across channels (email, surveys, Slack, notes)
ambiguous in intent or scope
debated instead of clarified
Before any decision can be made, teams must first answer:
What kind of feedback is this?
Is it actionable or ambiguous?
What issue is actually being described?
Many AI systems skip this step and jump directly to solutions. This agent focuses on the sensemaking gap between raw feedback and informed human decision-making.
Interaction / conversation strategy
This agent is not conversational by default.
Instead of responding like a chat assistant, it applies a deterministic workflow to user input.
The interaction model is intentionally simple:
The user pastes one or more pieces of feedback
The system processes the input step by step
Outputs are delivered as structured artifacts
There is no back-and-forth dialogue, follow-up questioning, or improvisation.
This design ensures:
predictable behavior
repeatable results
minimal cognitive load for the user
Voice & tone guidelines
The agent’s language is deliberately restrained.
Tone principles
Neutral, factual, and non-persuasive
No emotional amplification
No authoritative or directive phrasing
What the agent avoids
Opinions
Recommendations framed as decisions
Confident language when input is ambiguous
What the agent produces
Observations
Signals
Structured interpretations
The goal is to support clarity, not to simulate confidence.
Prompt & system design (conceptual)
The system prompt is designed as a behavioral contract, not a creative instruction.
Key design principles:
Treat all input as raw signal, not intent
Explicitly assess clarity before extracting insights
Separate interpretation from decision-making
Refuse to invent issues or actions when information is insufficient
The LLM operates inside a workflow where:
reasoning happens in a single, controlled step
outputs follow a strict structured schema
downstream actions are handled outside the model
This separation allows the system to remain predictable, testable, and extensible.
Workflow logic (high-level)
High-level workflow structure showing ingestion, analysis, and downstream outputs.
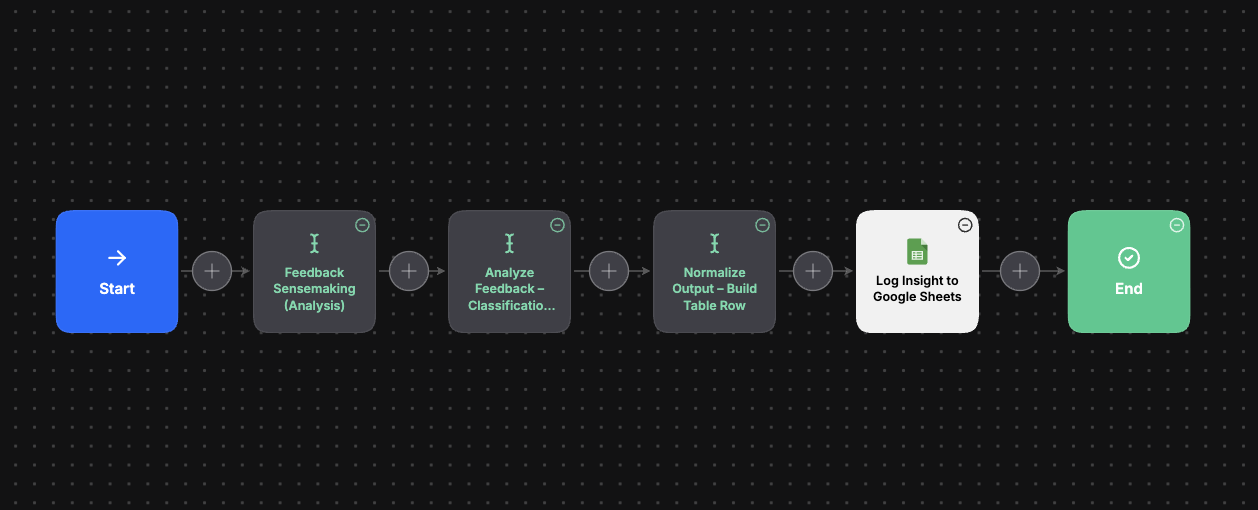
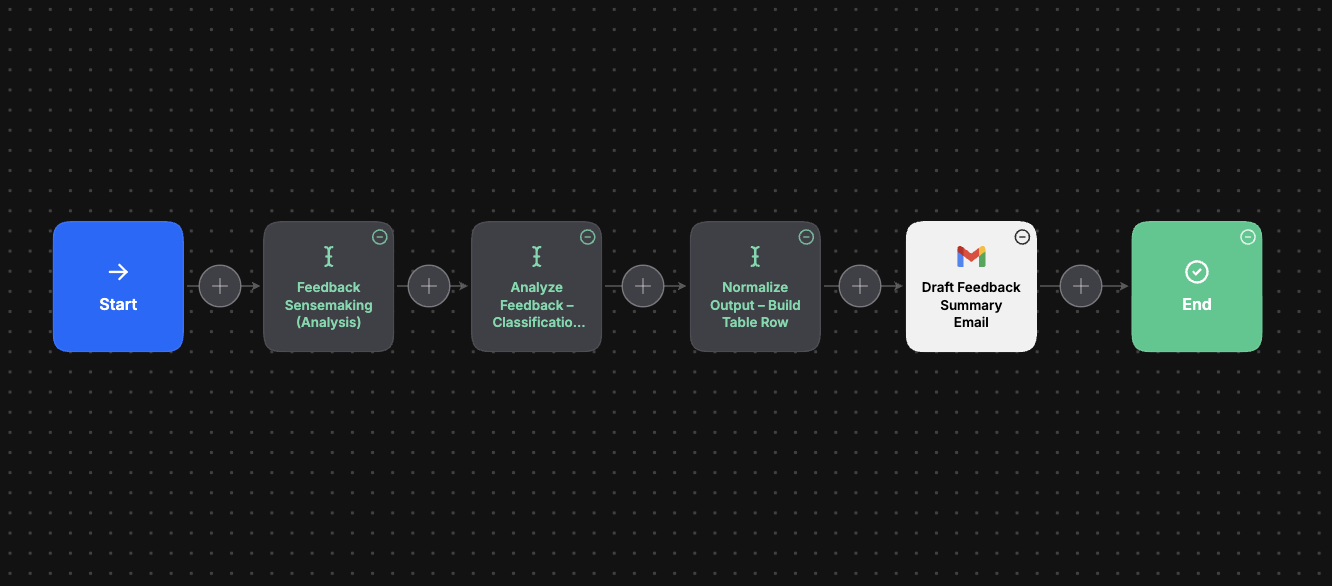
At a high level, the system processes feedback through the following stages:
Ingestion
Raw feedback is treated as data, without interpretation.
Classification
Feedback is categorized (e.g. UX issue, opinion, request).
Clarity assessment
The system determines whether the feedback is actionable or ambiguous.
Issue extraction
Concrete issues are isolated using neutral product language.
Signal surfacing
Possible next investigative actions and urgency indicators are generated.
Each stage has a single responsibility and clear constraints.
Observations from iterative testing
Iterative testing of the workflow and observation of interactions with the prototype revealed several consistent patterns, both in how people interpret the output and in how the system behaves when language becomes ambiguous.
These learnings sit at the intersection of UX clarity and language-based system design.
Key observations:
Semantic specificity matters more than tone
Inputs that clearly described what happened or where the problem occurred produced stable results, regardless of emotional language. Vague or meta statements (“not sure”, “just testing”, “I guess”) reliably triggered ambiguity gates.
Ambiguity needs to be surfaced, not resolved
When feedback contained unclear intent, the system was more trustworthy when it explicitly labeled the input as non-actionable rather than attempting to infer meaning. This reduced false confidence and improved interpretability.
Deterministic behavior increased perceived reliability
Running the same feedback through the workflow multiple times highlighted how important semantic determinism is. Consistent classification and issue extraction built trust, even when the outcome was “no issue identified”.
Small lexical changes can alter classification outcomes
Minor wording differences (for example, describing an experience versus questioning a behavior) affected how feedback was categorized. This reinforced the need for strict classification rules and precedence logic.
Explicit guardrails reduced semantic drift
Clearly defined constraints around what the system must not infer prevented overreach, especially in cases where feedback blended praise, uncertainty, and critique.
Long-form feedback produced more stable signals than short inputs
Multi-sentence feedback provided enough semantic context to support clearer classification and issue extraction, while single-line inputs were more likely to be flagged as ambiguous or opinion-based.
Scaling introduces new language risks
Testing batch inputs surfaced the need for additional stress testing around mixed-quality feedback, placeholder text, and edge cases that become more common at scale.
Integrations & outputs
Outputs
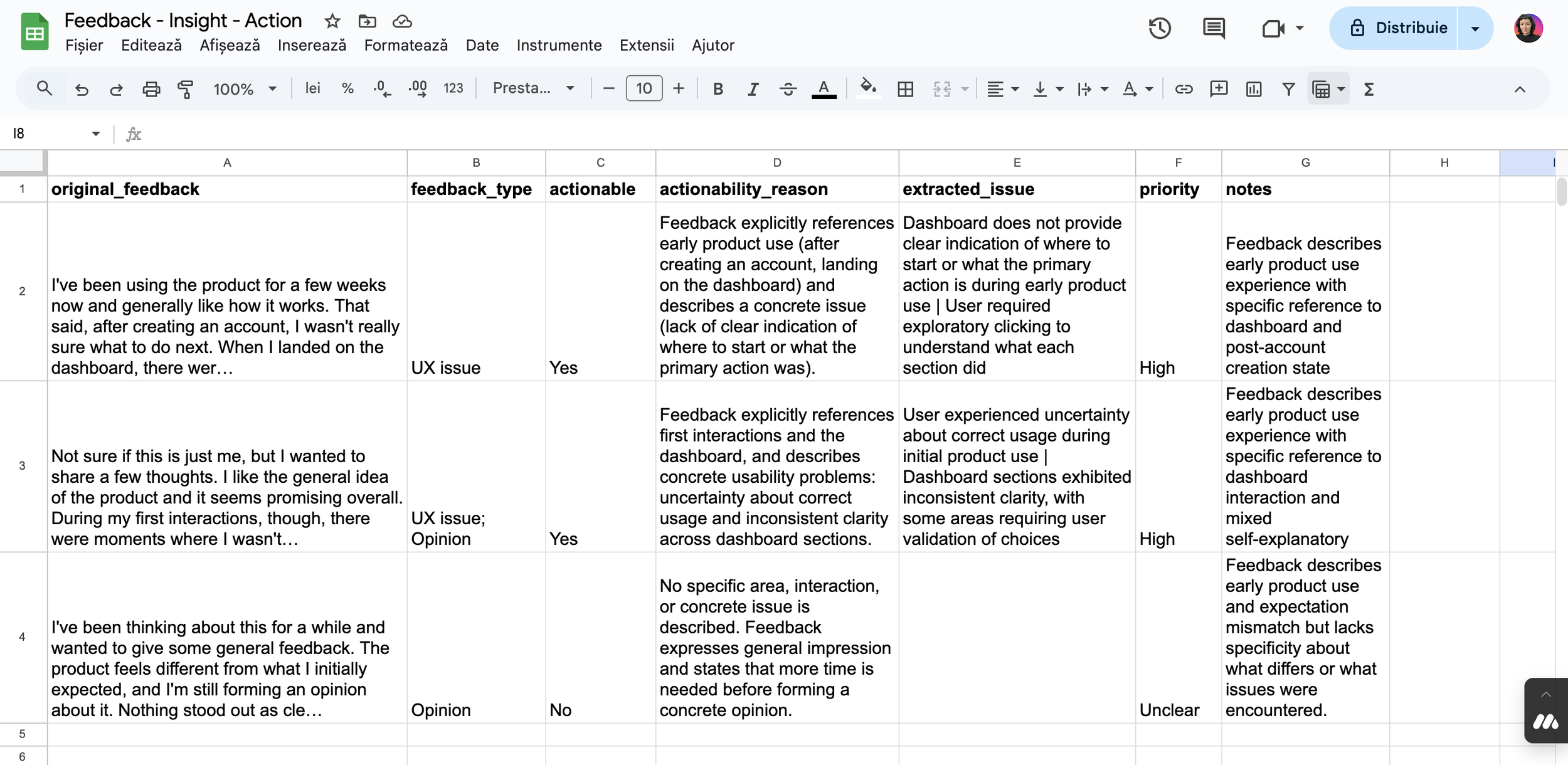
The system produces a normalized table that translates unstructured feedback into comparable signals, making it easy to review entries side by side or export them for spreadsheet-based analysis.
Integrations
Google Sheets – logging structured feedback for tracking and comparison
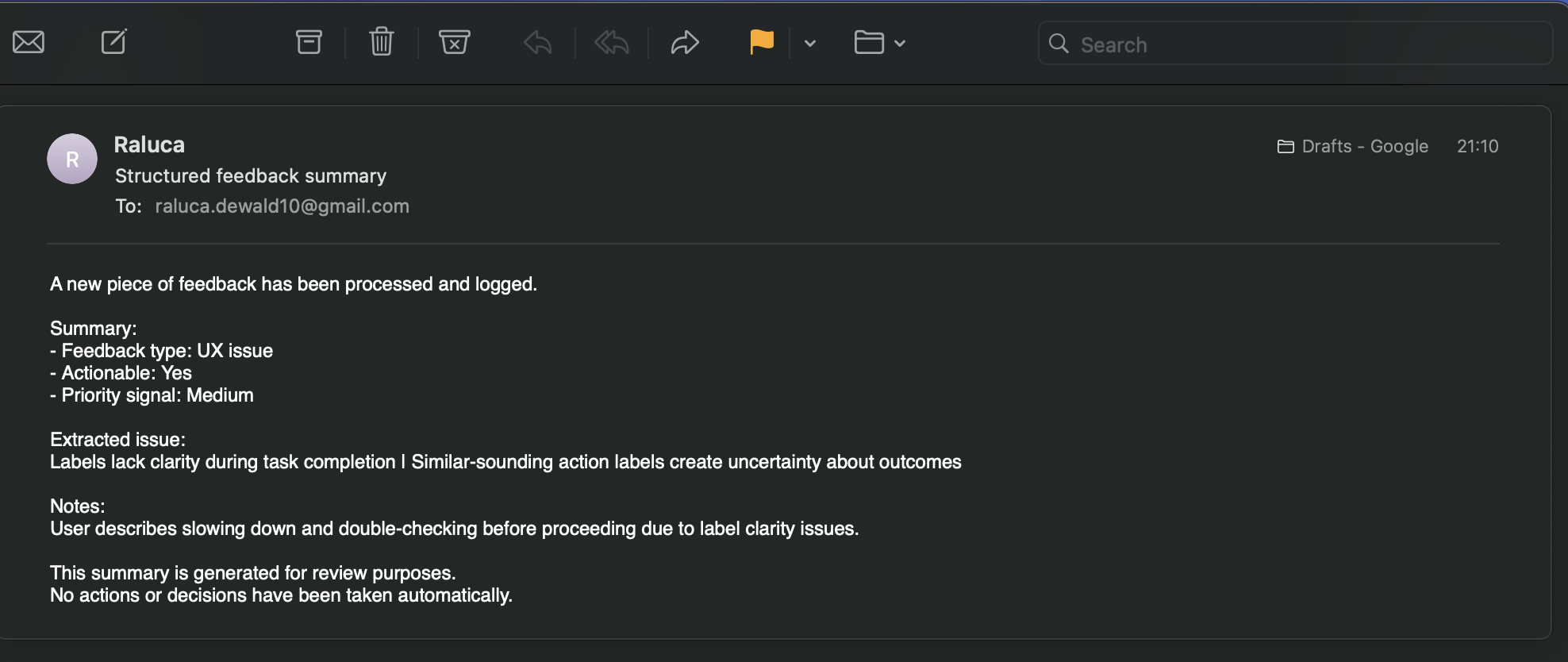
Email summaries – sharing structured insights for review and discussion
Workflow learnings
Testing the Google Sheets integration showed that most reliability issues came from how results were passed between steps, not from the model’s reasoning. Separating human-readable output from system-ready output, and enforcing a strict one-row structure for integrations, made the workflow significantly more predictable and easier to test.
Success criteria (conceptual)
Because this is an exploratory system, success is measured by quality of sensemaking, not automation speed.
Indicators include:
Ambiguous feedback is explicitly flagged, not over-interpreted
Clear feedback results in specific but restrained outputs
Similar inputs produce consistent structures
Outputs can be reviewed without additional explanation
The system avoids solutioning and overreach